Big Data File Formats
- Why do we need different file formats?
- Apache Avro
- Apache Parquet
- Apache ORC
- Avro vs Parquet
- Parquet vs ORC
Big Data File Formats
Silent Reading Time: 5 mins 44 secs
This blog summarises three major file formats for Big Data primarily used in the Hadoop File System.
Why do we need different file formats?
A key consideration for HDFS-enabled applications, such as MapReduce or Spark, is the time it takes to find data in one location and then to write the data to another location. This is further complicated by changing schemas and storage considerations.
Big Data storage costs tend to be higher due to storing files redundantly: add in the processing costs and the requirement to scale all of this as your data increases and your file formats can become a pretty big deal.

Over time, various file formats have been created to resolve or reduce these issues. Choosing an appropriate file format can have some significant benefits:
- Faster read times
- Faster write times
- Splitting files
- Schema evolution
- Advanced compression
Apache Avro

Apache Avro is a data serialization format for record data developed within Apache’s Hadoop project. It can be used with Java and other JVM languages such as Scala, as well as Python, C/C++/C#, PHP, Ruby, Rust, JavaScript and Perl.
What is data serialization?
Data serialisation is the process of converting a data object into a series of bytes. In the serialised state (bytes), the data can be delivered easier to another data store, application, or some other destination.
We also need to be able to de-serialise the data once it’s been received. The de-serialisation process recreates the object, making the data easier to read and modify as a native structure in a programming language.
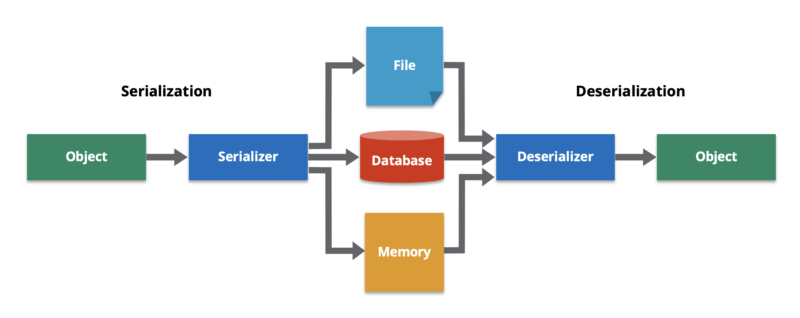
What is in an Avro file?
An Avro file, or Avro Object Container File, contains of a file header, followed by one or more blocks of data.
The file header is made up of:
- Four bytes followed by the Avro version number
- File metadata, including the schema definition
- A randomly-generated sync marker for this file
For data blocks Avro can use one of two serialisation encodings: binary and JSON. Most applications use the binary encoding, as it is smaller and faster
An Avro file must always contain it’s schema, a file with no schema is an invalid Avro object.
Avro schemas are defined using JSON and can contain complex types such as arrays. Simple schema example:
{
"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [{
"name": "name",
"type": "string"
}, {
"name": "favorite_number",
"type": ["null", "int"]
}, {
"name": "favorite_color",
"type": ["null", "string"]
}]
}
With Avro, the “writer” (application serialising the data) and the “reader” (application de-serialising the data) don’t need to use the same schema: as long as the two schemas are compatible. Avro resolves the differences by looking at the writer’s schema and the reader’s schema and translating the data from writer’s schema into reader’s schema.
For example, if the “reader” encounters a field that appears in the “writer’s” schema but not in the “reader’s” schema, it will be ignored.
If the “reader” expects some field but the “writer’s” schema does not contain a field of that name, it is filled in with a default value declared in the “reader’s” schema.
To maintain this kind of compatibility, you may only add or remove a field that has a default value. If you added a field that has no default value, new “readers” would not be able to read data written by new “writers”, so you would break forward compatibility. If you removed a field that has no default value, old “readers” wouldn’t be able to read data written by new “writers”, so you would break forward compatibility.
This can mitigate the impact of schema drift, especially when used with a schema registry which enforces full compatibility.
Apache Parquet

Apache Parquet is a column-oriented data storage format. It was created as part of the Apache Hadoop project to utilise compressed, columnar data representation; being specifically designed to support complex nested data structures, using the shredding and assembly algorithm from Dremel; which may be familiar to you as a core component of BigQuery.
Parquet is used to store large datasets efficiently and is a popular file format in Hadoop systems such as Pig, Spark and Hive.
Like Avro, Parquet can be used with Java and other JVM languages such as Scala, as well as Python, C/C++/C# and PHP.
What is a columnar data store?
A columnar data store stores data in columns instead of rows. This enables efficient read and write of data to and from disk speeding up the time it takes to return a query. This approach greatly improves disk I/O performance and is particularly helpful for data analytics and data warehousing.
Columnar data store vs. row-oriented data store
Column-oriented data stores and row-oriented data stores are both methods for processing data in data warehouses. However, they have different approaches: while column-oriented data is stored in columns, row-oriented data is stored in rows (surprisingly!).
The main benefit of a columnar database is faster performance compared to a row-oriented one; this is because it accesses less memory to output data.
As the initial data retrieval is done on a column-by-column basis, only the columns that need to be used are retrieved. This makes it possible for a columnar database to scale efficiently and handle large amounts of data.
The storage of individual columns also allows data to be stored in smaller sizes.
This approach does have limitations, such as performance impacts to incremental loads and OLTP.
However, as in-memory data applications become more prevalent the pros/cons of column vs row storage become less of a concern due to efficient read and write to disk not being as important.
Back to Parquet…
In Parquet values in each column are stored in adjacent memory locations meaning column compression is more efficient in storage space and queries that fetch specific column values need not read the entire row, improving performance
Compression is performed column by column, which enables different encoding schemes to be used for text and integer data. This strategy also keeps the door open for newer and better encoding schemes to be implemented as they are invented.
Apache ORC

Apache ORC (Optimized Row Columnar) is another column-oriented data storage format used with the Hadoop ecosystem. Similar to Parquet it is used extensively with Spark and Hive.
Who are Apache?
Considering most of what I’ve covered is Apache software, who are they and why do they have so many similar tools?
The Apache Software Foundation is an American non-profit corporation which a supports and promotes the use of open source software projects. Apache projects are characterised by a collaborative, consensus-based development process. Each project is managed by a self-selected team of technical experts who are active contributors to the project.
With ORC and Parquet, Hortonworks (the main contributors to Hadoop: Horton is the name of Hadoop’s elephant logo) collaborated with Facebook to lead the development of ORC while, only a month later, Twitter and Cloudera (also heavily involved in The Hadoop ecosystem) developed Parquet.
Designed to overcome the limitations of other file formats, ORC stores data compactly and enables skipping over irrelevant parts (predicate pushdown) without the need for large, complex and manually maintained indices.
What is in an ORC file?
An ORC file contains grouped rows of data, called stripes. The default stripe size is 250mb but larger stripes enable larger and more efficient reads in Hadoop File System (HDFS).
It also contains additional metadata in a footer:
- A list of all stripes
- The number of rows per stripe
- The data type of each column
- Finally, a postscript holds compression parameters.
Predicate Pushdown
The concept of predicate pushdown is that certain parts of SQL queries (the predicates) can be “pushed” to where the data lives. This optimization drastically reduces query processing time by filtering out data earlier rather than later.
Depending on the processing framework, predicate pushdown can optimize your query by doing things like filtering data before it is transferred over the network, filtering data before loading into memory, or skipping reading entire files or chunks of files.
A “predicate” is a function that returns a boolean (true or false). In SQL queries predicates are usually encountered in the WHERE clause and are used to filter data.
Avro vs Parquet
- Avro is a row-based storage format. Parquet is column-based storage formats
- Parquet reads are much more efficient than Avro, meaning it is better for analytical queries.
- Writing is more efficient in Avro
- Avro has a more mature schema evolution, Parquet only supporting schema append
- Parquet is ideal for querying a subset of columns
- Avro is ideal in ETL, where we query all columns
Parquet vs ORC
- Parquet is more capable of storing nested data
- ORC is more capable of Predicate Pushdown
- ORC supports ACID properties, guaranteeing data validity despite errors
- ORC uses more efficient compression
apache big-data hadoop